Flow 5.0.0
Highlights
New general-purpose image search
Flow 5 includes a new powerful AI model for general-purpose image search. It provides much better retrieval quality and is much faster at the same time.
![]()
The model is trained for general image search and tries to find the same objects as in the input image. If this is not possible, the model attempts to find images with similar high-level concepts.
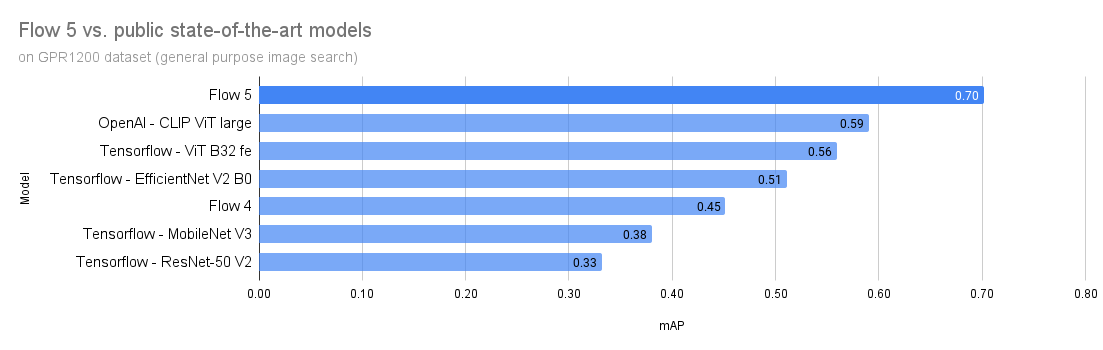
The new general-purpose model of Flow 5 performs almost twice as well as Flow 4. Furthermore, our model outperforms current state-of-the-art image retrieval models as visualized in the graph below.
New duplicate detection
Flow 5 ships with a dedicated AI model specialized in detecting duplicate images.
The new model has the ability to identify near-duplicate images, even if they have been modified several times. These modifications include changes to saturation and color, alterations in size, and conversion to a different image format. Flow 5 can also identify rotated images, blurred images, cropped images, and images with added text. Furthermore, the model is able to recognize images with JPEG compression artifacts and partial copies, where a part of an image is included in a composite image.
![]()
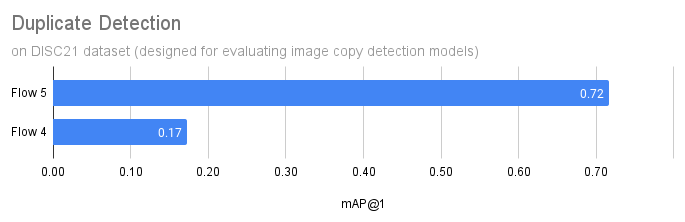
Overall, Flow 5 is able to identify near-duplicate images with a high level of accuracy. The probability of finding an existing duplicate is four times higher than with Flow 4.
New approximate search mode
Added approximated search method rank.approximate.
The new search algorithm consists of a data reduction algorithm (the improved Smartfilter), an approximate ranking algorithm (called LOPQ) and a step to re-rank the top-50 approximated results by exact ranking.
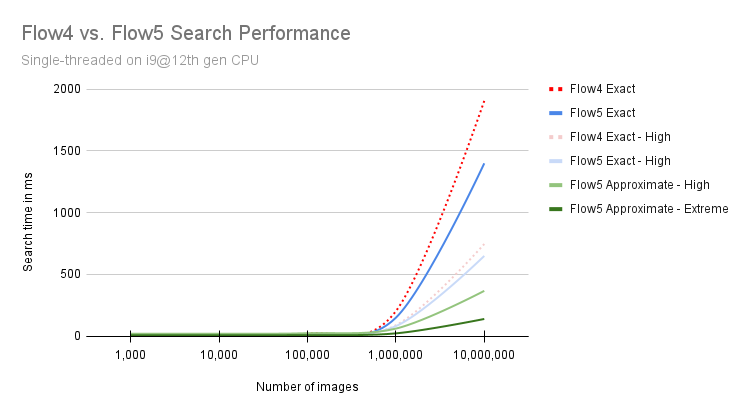
This leads to much higher search speeds - especially in large image sets - with excellent search quality. For example, the probability that the best result of an exact search is also found in an approximated search is 93% on average, although only 2% of the data is actually ranked (with Smartfilter high).
Flow5 is so much faster than Flow4, allowing huge image collections to be searched quickly on a single node. Using approximate search, searching through 10 million images literally takes the blink of an eye (140ms).
New color search
Flow 5 ships with a brand new color extraction algorithm to allow new filters based on colors and backgrounds as well as new similarity searches. Accent colors are emphasized, making it possible to find images that contain little of an accent color. This leads to greater variability of search results.
![]()
Background detection

Detection of isolated content. You can filter by isolated content to search for marketing material with a uniform background which can be easily removed.
Color palette
 Extracts a color palette of up to 5 dominant colors. Our algorithm emphasizes vibrant colors so that accent colors are part of the color palette even if they occupy only a small part of the image.
Extracts a color palette of up to 5 dominant colors. Our algorithm emphasizes vibrant colors so that accent colors are part of the color palette even if they occupy only a small part of the image.
The algorithm works automatically in a two-step mode. It tries to extract the exact colors (e.g. in logos or vector graphics). If there are too many colors (for example in photos), it tries to extract the color mood and keep accent colors.
If a detected background is not colored then it is not part of the color palette and considered technical (not important to the actual image content).

For each color of the color palette, its share in the overall image is determined and saved.
Color names
The color palette is matched against a predefined list of 12 basic colors to find their associated color names. These color names can be used as keywords for search filters or in the faceted search.

Shades & tints of a color are mapped to the same name. The idea is to have a limited number of color buckets suitable for coarse filtering.
Better Smartfilter
The Smartfilter algorithm reduces the amount of data that actually needs to be searched (so called search space). Based on the entered search query and the Smartfilter level, images that are most likely irrelevant for this search query are not included in the evaluation. This speeds up search times tremendously.
The subdivision of the search space is now twice as fine and calculated using 30x more data. This ensures more powerful filtering, especially for large collections. The recommended filter setting high reduces the amount of data to be searched by 98% on average.
We also added a new filter level ultra to integrate an intermediate step in the filter strength between high and extreme. Depending on your dataset size you can choose between filter levels: extreme, ultra, high, medium and low.
Faster image analysis
Flow 5 has to process more algorithms and AI models than Flow 4 when analyzing an image, but is still faster, resulting in faster indexing and query preparation.
This is due to the use of several techniques:
- Use of highly optimized native codes for efficient matrix computations including hardware acceleration on modern CPUs.
- Use of lightweight AI models (although they are more powerful than their predecessor models).
- Improved image loading and decoding pipeline.
We have improved the image loading and image preparation mechanism to increase performance by up to a factor of 2. In particular, when using high-resolution images, we have drastically reduced processing time by applying subsampling when decoding the image and downscaling the image in multiple steps to preserve as much detail as possible.
These measures also improve search speed when searching by image upload or image URL.
Copy space detection
With the new copy space API, it is easier to search for images with
copy space. Now, you only need the copyspace field to filter for images with copy space in individual image areas.
New HTML response format
Json is great but not expressive when it comes to images. The new HTML response writer is useful to easily check visual search results without having to implement a user interface first. Set wt=html in your query and inspect the results right in your browser.
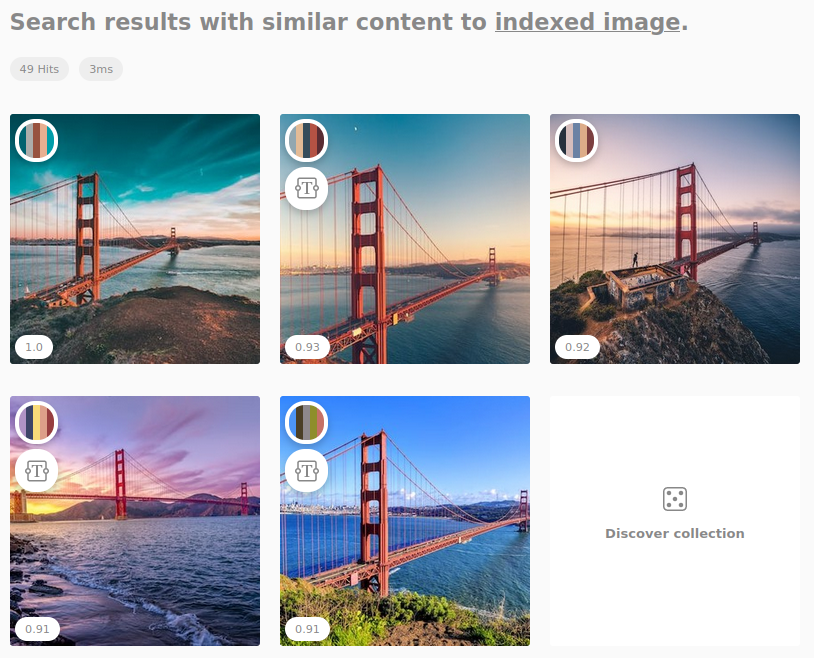
Depending on the returned fields and query parameters the HTML response writer supports displaying facets, scores, detected copyspace, color palette and detected isolated content.
To ease explorative search you can also trigger visual search requests by clicking on result images or perform a random search to discover your collection.
Minor features and improvements
- We updated Tensorflow to 2.10.1 that enables x86-64 CPU hardware acceleration for performance critical operations via oneAPI Deep Neural Network Library (oneDNN). This speeds up image analysis on modern CPUs using features such as AVX512_VNNI, AVX512_BF16, AMX, and others.
- New API documentation. We have rewritten the entire documentation and switched the underlying framework to provide a more powerful search and better user experience. We've added more examples focused on specific use cases with a sample dataset so you can easily replicate the search features.
- Added new parameter
downloader.userAgentto set a specific user agent sent when downloading images. This can be useful when an image server allows access based on the user agent. - Added endpoints with useful default parameters suited for specific search functions (
/image,/color,/duplicate). You can still override all parameters or use the general/selectendpoint. - Replaced
rank.mode=defaultwithrank.mode=contentto better describe the operating method of the ranking algorithm. /analyzehandler parameterinput.urlsrenamed toinput.urlto reflect only single URL support.- Replaced
rank.by=key:valueparameter torank.by.key=value(e.g.rank.by.id=1) to better conform to standard HTTP query parameters and ease usage in some use cases like uploads. - Java API:
SimpleOutputProduceronly accepts one image per call. /analyzehandler response format changed. More compact data representation.taghandler response format changed. More compact data representation. Default configuration changed to predict single tags instead of a tag cloud.
Upgrade from 4.x
With Flow 5.0.0 we drop the support for Solr 6.x. Please update Solr to the latest supported version to be able to update Flow and to benefit from the latest bugfixes and performance improvements provided by Solr.
Reindexing
Due to new analysis algorithms and storage structure reindexing is necessary.
Changed configuration
To update the schema and solrconfig.xml configuration please use these snippets.
We removed the pxl_ prefix from default field.prefix configuration. Now, created fields and fieldtypes have no prefix by default.
This also means, that the special field pxl_import is now addressed without prefix (import).
| Flow 4.x | Flow 5.0 |
|---|---|
field.prefix=pxl_ |
field.prefix= |
downloader.kBytesPerSecPerCon |
removed |
downloader.maxConnections |
removed |
Changed API endpoints
All API endpoints can be configured. The table below lists the changes to the default configuration.
| Flow 4.x | Flow 5.0 |
|---|---|
/tagging |
/tag |
/image |
|
/color |
|
/duplicate |
Changed API parameter
| Flow 4.x | Flow 5.0 |
|---|---|
rank.by=id: |
rank.by.id |
rank.by=url: |
rank.by.url |
rank.by=data: |
rank.by.data |
rank.by=hex: |
rank.by.hex |
rank.mode=default |
rank.mode=content |
rank.smartfilter=normal |
rank.smartfilter=medium |
input.urls |
input.url |
dup.find |
removed, use rank.by.* |
dup.threshold |
removed, use rank.threshold |
textspace.true |
removed, use fq=copyspace:* |
textspace.operator |
removed |