/duplicate endpoint

Use the /duplicate endpoint to scan the collection for duplicate images using external images or the images already in the collection.
Detect exact duplicates only or near-duplicates as well.
The examples below require the example dataset.
Single scan

Check whether the image 115 has duplicates in the collection using the /duplicate endpoint.
http://localhost:8983/api/cores/my-collection/duplicate?rank.by.id=115
Full scan
Scanning the complete collection by comparing all images against each other is more complex than a single scan. The process for a full scan is:
- Retrieve all image ids in the collection
- For each id scan for duplicates in the collection
- If duplicate images are found add those in a graph as nodes and connect them via edges.
- Once all images have been processed identify isolated groups of duplicates in the graph.
- For each duplicate group save the URIs to each image in a JSON file.
Once the duplicates are detected, you can implement action policies like deleting images, merge them etc.
Since the above steps are quite a few, we provide you a python project dupe-scanner on Github.
Clone the repo:
git clone https://github.com/pixolution/dupe-scanner
Follow the setup instructions and scan with the example dataset or index your local files to detect duplicates.
(venv) user@laptop:~/dupe-scanner$ python scanner.py scan
Process 1562 images. Start scanning (this may take a while)...
100%|██████████████████████████████████████| 1562/1562 [00:19<00:00, 81.88scans/s]
Export 31 duplicate groups to duplicates.json...
Detected 77 duplicate images. Export results to duplicates.html ...
100%|███████████████████████████| 77/77 [00:06<00:00, 12.10thumbnails generated/s]
Open the generated duplicates.html in your browser and inspect the detected duplicate clusters of your collection.

Partial scanning
Sometimes you want to search for duplicates only in a subset of the collection.
To restrict the scan, just add one or more filter queries (fq) to your query.
You may include only docs that are tagged with a certain term (e.g. fq=category:project-a) or exclude them (search in all other projects but project-a by setting fq=category:project-a). You can also search in specific date ranges.
This may be useful to either speed up the scan be reducing the number of docs that have to be scored or to be more specific where to search.
The query below scans for door images that are duplicates of image id 1041.
Furthermore, the query image itself is excluded from search.
http://localhost:8983/api/cores/my-collection/duplicate?
rank.by.id=1041
&fq=labels:door
&fq=-id:1041
One duplicate image is found.
{
"responseHeader":{
"status":0,
"QTime":6},
"response":{"numFound":1,"start":0,"maxScore":0.7436813,"numFoundExact":true,"docs":[
{
"id":"1051",
"image":"https://docs.pixolution.io/assets/imgs/example-dataset/door/photo-1581613856477-f65208436a48.jpeg",
"score":0.7436813}]
}
}
Detection sensitivity
Depending on your use case you may have various definitions what a duplicate actually is. With the rank.treshold parameter you can set the detection sensitivity and control whether to only retrieve exact duplicates or near-duplicates as well.
Exact duplicates may have a different scale, file format or compression artifacts but basically encode the same image content.
Near-duplicates additionally may include manipulations to the image content, like cropping, different aspect ratio, changes to brightness, gamma and saturation, added decorations like text, logos or icons.
The threshold depends on your image content as well as your definion of a duplicate. As a guideline you may set the following rank.threshold values based on your use case:
- Exact duplicates only:
0.95 - Near-duplicates:
0.7
Scanning huge collections
Scanning a complete collection is a time consuming process which has to be done offline. Depending on the hardware and collection size it can take hours to process. Most often, this is only necessary once to initially de-dupe an existing dataset. Subsequent operation should then scan before adding new images to the collection to keep the dataset clean.
Reducing scan time is always a trade-off between time and detection quality.
We propose two scan modes: balanced & speed which both suggest different parameter values for rank.approximate and rank.smartfilter based on the collection size.
The python snippet find-duplicates.py implements both scanning modes (see full scan).
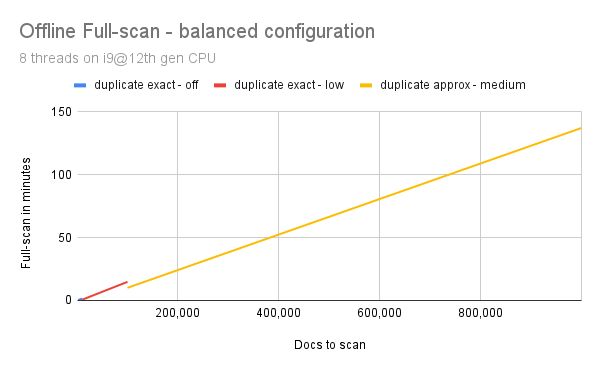
- up to 10,000 docs use
rank.approximate=false&rank.smartfilter=off - up to 100,000 docs use
rank.approximate=false&rank.smartfilter=low - from 100,000 docs use
rank.approximate=true&rank.smartfilter=medium
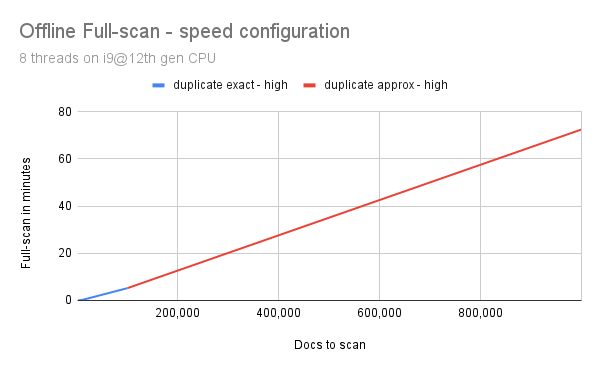
- up to 100,000 docs use
rank.approximate=false&rank.smartfilter=high - from 100,000 docs use
rank.approximate=true&rank.smartfilter=high
When using rank.approximate=true you have to manually remove irrelevant matches from the result set that do not meet a required score threshold. The provided find-duplicates.py snippet automatically does this for you.
Maintain a clean image collection
To keep your collection free of duplicates, scan new images to check if they already exist before you index them. Based on the response, you can take various actions, such as rejecting the new document, adding a link to the existing document IDs, forcing user input, or overwriting the existing document.
The graph below shows the process how to efficiently scan before indexing a new doc. The idea is that an image should be analyzed only once to avoid repeated analysis steps and to reuse the preprocessed json data throughout the workflow.
graph LR
A[Client]
B[Flow /analyze endpoint]
C[Flow /duplicate endpoint]
D[Flow /update endpoint]
A <==>|1. Analyze image| B
A <==>|2. Scan for duplicates | C
A ==>|3. Index Json| D- Analyze image
- Use preprocessed json to scan for duplicates (
rank.by.preprocessed) - use preprocessed json to index doc, if it does not exist
Use Cases
E-commerce
Finding near-duplicate images can help identify products that are being sold by multiple vendors, making it easier to manage inventory and ensure product authenticity.
Media and entertainment
Finding near-duplicate images can help identify copyright violations and protect intellectual property rights for content creators.
Stock photography
Automatically identify and reject image uploads of previously flagged and rejected images of content creators.
Real estate
Identify fraudulent image uploads (fake listings) on the marketplace by matching them with verified users' images, identify duplicate listings for the same home or property if imported from multiple sources.
Digital asset management
Prevent multiple uploads of different users or associate different version of an image. Dedupe existing image collection.